Exchange 2013 Rocks and its unfair from my part if I don’t talk about it. Please find some of the below link which has some high-level overview on Exchange 2013
Regards,
Krishna

Exchange 2013 Rocks and its unfair from my part if I don’t talk about it. Please find some of the below link which has some high-level overview on Exchange 2013
Regards,
Krishna
Exchange 2010 has come up with lots of interesting and advanced features and one of the most important features is HA. Being exchange one of the most mission critical application of any organization, it’s important that we must have a strong HA solution for any kind of issues. It can be either server failure or a complete Site Failure
Most of your would have gone through the DAG features which provides us with the HA flexibility with in the same site and across the site for the MAILBOX role servers. There are other important server’s roles which mailbox server depends and it’s very important that we plan HA for them as well and they are CAS role and HUB role server. HUB role are designed with HA by default using active directory. If any server HUB server fails in a site then other HUB servers are used and during the site failure all the email will be routed to the new HUB servers in the DR site and if there are multiple HUB servers they are load balanced in round robin fashion.
Let’s talk about the CAS servers with HA and DR flexibility. Exchange 2010 has come up with the new HA for CAS server and it is called as CAS Array. Outlook uses this CAS Array to configure the outlook. You may already know that outlook uses CAS server for the MAPI connection. CAS Array allows you to add all the CAS servers into the array with behind the load balancer and expose the Virtual IP (VIP) for the user connection. Load balancer poles all the CAS servers in the array and if there is any server down then user connection will not directed to the failed CAS server until it comes up. In this fashion we have HA flexibility within the site when we have one or more CAS server failure.
Highlight of this article is to find how CAS Array works when there is a site failure in a DR Scenario which we don’t find much information around.
Let’s consider a scenario, we have 2 AD site. First is the primary site with the name SiteA and second is the DR site with the name SiteB. Below Table 1 shows the details of the CAS Array with their site specific names and there corresponding IP address

If there is failure of siteA then with the help of DAG we mount all the database on the server in the SiteB(DR Site) with this user will not have the outlook connected. They will still be in disconnected state, because all the users’ outlook is configured with PrimaryCASArray.domain.com and it is down because of the site failure.
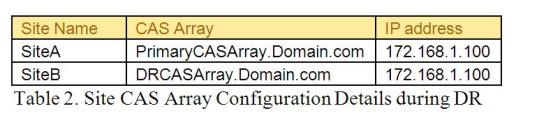
Now it’s not feasible configure the entire database in SiteB (DR site) with the new CAS Array DRCASArray.domain.com and reconfigure the entire user’s outlook with new CAS array name. This is not a solution any company would require for DR and it doesn’t look good even from the design prospective. Ideal and simple solution is to change the DNS IP address of PrimaryCASArray.Doamin.com with the SiteB IP address 172.168.1.100. May need to wait for some time for the replication and soon you should find user outlook coming online. Table 2 shows the new IP address on PrimaryCASArray.domain.com during DR. Once you wanted to failback to the primary site (SiteA) then we have again revert the CAS array IP address to the old state as defined in the Table 1.
I am sure many would have had this query in your mind as I had and hope this article helps you in design a solution depending on your requirement.
There is a small presentation on Exchange 2007 HA and DR by myself (Krishna kumar) and Windows 2008 R2 VDI Over view by MR Ravikanth at Bangalore Microsoft Co-orporation , Signature Building
http://bitpro-fbevent.eventbrite.com/

Kindly register yourself and please attend the same
